 مدرسه تخصصی اقتصاد |
مدرسه تخصصی اقتصاد |
نحوه انجام رگرسیون خطی به روش OLS در Stata، از ساده ترین مدل های اقتصاد سنجی است. برای انجام رگرسیون خطی OLS ابتدا باید داده ها را وارد نرم افزار کنیم. سپس داده ها را آماده تجزیه و تحلیل کنیم.
نحوه وارد کردن داده ها به نرم افزار استاتا را در مقاله ای دیگر توضیح داده ام. در این مقاله با هم مراحل انجام رگرسیون خطی به روش OLS در Stata را یاد میگیریم.
این کار را با یک مثال شروع می کنیم ، برای وارد کردن داده ها کد زیر را در قسمت کامند استاتا وارد می کنیم و با اجرای این کد، داده های مورد نظر وارد نرم افزار می شوند.
use https://www3.nd.edu:443/~rwilliam/statafiles/reg01.dta
بعد از وارد کردن داده ها در stata، آمارهای توصیفی را از راه های مختلف می توانیم بررسی کنیم. در اینجا ما همبستگی متغیرها را مورد بررسی قرار می دهیم و در صورت وجود همبستگی یا وجود داده های پرت، آنها را از مدل حذف می کنیم. از دستور زیر می توانیم برای این کار استفاده کنیم.
correlate income educ jobexp race, means
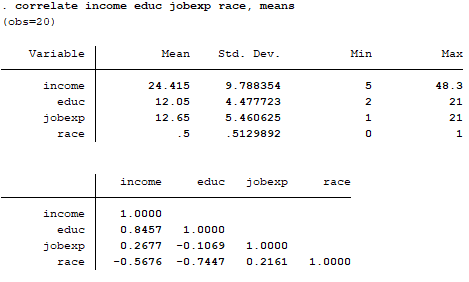
نحوه انجام رگرسیون خطی به روش OLS در Stata
در این قسمت رگرسیون خطی را برآورد می کنیم. در حالت عادی به طور پیش فرض نرم افزار استاتا ضرایب را استاندارد نشده برآورد می کند.
regress income educ jobexp race
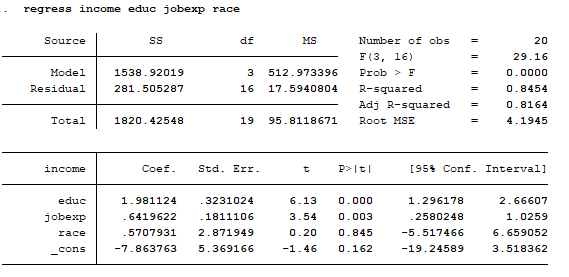
تفسیر نتایج رگرسیون OLS
بعد از برآورد مدل به تفسیر نتایج آن می پردازیم.
تفسیر ضرایب یا coef. : ضرایب برآورد شده نشان دهنده تغییر در متغیر وابسته مرتبط با تغییر یک واحدی در متغیر مستقل است. ضرایب مثبت نشان دهنده رابطه مثبت و ضرایب منفی نشان دهنده رابطه منفی است. برای نمونه در مثال بالا متغیر educ رابطه مثبت و معنا داری با متغیر income دارد. و هر یک واجد تغییر در educ، حدود 1.98 درصد متغیر income تغییر می کند.
std. Err : خطای استاندارد عدم قطعیت در ضرایب برآورد شده را نشان میدهد، هرچقدر خطای استاندارد کمتر باشد، یعنی تخمین ضرایب دقیق تر است.
آماره t: هرچقد آماره t بزرگتر باشد، ضرایب برآورد شده معنادار تر هستند.
p>|t | : پراب های کمتر از 0.05 درصد نشان دهنده ضرایب برآورد شده معنادار در سطح 95 ٪ است.
بررسی مناسب بودن مدل:
آماره R2 نسبت واریانس در متغیر وابسته که توسط متغیرهای مستقل توضیح داده می شود را اندازه گیری می کند. هر چقدر آماره R2 نزدیک به عدد 1 باشد، نشان دهنده مناسب بودن مدل است. ولی نباید به این معیار اکتفا کنیم.
آماره R2 تعدیل شده، تعداد متغیرهای توضیحی مدل را تنظیم می کند.
آماره F حالت کلی مدل رگرسیون را بررسی می کند، معنادار بودن F نشان می دهد حداقل یکی از متغیرهای مستقل رابطه معناداری با متغیر وابسته دارد.





