 مدرسه تخصصی اقتصاد |
مدرسه تخصصی اقتصاد |
راهنمای گام به گام رگرسیون خطی ساده و چند متغیره در R با حل یک مثال کامل
رگرسیون خطی، از یک خط مستقیم برای توصیف رابطه بین متغیرها استفاده می کند. به طوریکه با جستجوی ضرایب مدل که خطای کل را به حداقل می رسانند، بهترین خط یا بهترین برازش را پیدا می کند.
مدل های رگرسیون خطی دو نوع هستند:
رگرسیون خطی ساده، تنها از یک متغیر مستقل استفاده می کند و رگرسیون خطی چندگانه، از دو یا چند متغیر مستقل استفاده می کند
در این نوشته، با هم هر دو مدل خطی ساده و چندگانه را با حل یک مثال آموزش می بینیم.
دیتاست آموزشی زیر را برای انجام رگرسیون خطی ساده و رگرسیون خطی چندگانه آماده کرده ایم.
ابتدا روی لینک های بالا کلیک کنید و داده ها را دانلود و سپس در یک مسیر مشخص در کامپیوتر یا لپ تاپ تان ذخیره نمایید.
شروع کار در R
اگر تا به حال برنامه R را در کامپیوترتان نصب نکرده اید از مقاله نحوه دانلود و نصب برنامه R اقدام کنید.
اگر تا به حال برنامه R را در کامپیوترتان نصب نکرده اید از مقاله نحوه دانلود و نصب برنامه R اقدام کنید.
پس از نصب و راه اندازی R، کتابخانه ها یا package های مورد نیاز برای کار با داده ها و حل مدل را نصب می کنیم. برای راحتی کار در برنامه Rstudio از مسیر File > New File > R Script را باز می کنیم.
برای انجام مراحل کار می توانید به راحتی کدهای موجود را کپی و در قسمت R Script پیست کنیم. روی هر خط که می خواهیم کد اجرا شود، کلیک می کنیم و بعد روی دکمه run در قسمت راست بالا کلیک می کنیم. با این کار کدهای ما در محیط R اجرا می شوند. یا می توانیم با فشار دادن همزمان دکمه های ctrl + enter در صفحه کلید، کدهای مورد نظر را اجرا کنیم.
ابتدا کتابخانه ها یا package های لازم برای تحلیل مدل را نصب می کنیم. کدهای زیر را قسمت R Script تایپ یا پیست کنید و اجرا کنید.لازم برای نصب package در R سیستم به اینترنت متصل باشد.
<span style="font-size: 12pt;">install.packages("ggplot2")
install.packages("dplyr")
install.packages("broom")
install.packages("ggpubr")</span>
بعد از نصب این کتابخانه ها باید آنها را در محیط R فراخوانی کنیم.
<span style="font-size: 12pt;">library(ggplot2) library(dplyr) library(broom) library(ggpubr)</span>
قدم اول: بارگذاری یا فراخوانی داده ها در R
1- برای وارد کردن داده ها در Rstudio از منوی File > Import dataset > From Stata اقدام می کنیم.
2- سپس فایل مورد نظر که قبلا دانلود کرده ایم را از قسمت brows انتخاب می کنیم.
3- در قسمت data preview داده ها و متغیرها را می توانیم مشاهده کنیم. اگر داده ها درست باشند می توانیم در مرحله پایانی روی گزینه Import کلیک کنیم و داده ها را وارد R کنیم.
بعد از وارد کردن دیتا می توانیم خلاصه ای از داده ها را با دستور ()Summary ببینیم.
رگرسیون خطی ساده
summary(income.data)
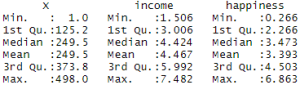
رگرسیون خطی چندگانه
summary(heart.data)
با اجرای این تابع ، جدولی از داده های خلاصه شده که شامل مقدار حداقل، میانه، میانگین و حداکثر را برای متغیرهای مستقل و وابسته نشان می دهد.

قدم دوم: بررسی فروض اساسی در مدل خطی
باید مطمئن شویم که داده های ما چهار فرض اساسی برای انجام رگرسیون خطی را تامین می کند. از قبیل واریانس همسانی، استقلال مشاهدات (مطمئن شویم که هیچ رابطه پنهانی بین متغیرها وجود ندارد)، نرمال بودن داده ها و وجود رابطه خطی بین متغیر مستقل و وابسته.
1- استقلال مشاهدات( عدم وجود خود همبستگی)
در این مدل چون ما فقط دو متغیر داریم، نیازی به چک کردن این فرض عدم وجود خود همبستگی نداریم.
2- Normality
جهت بررسی نرمال بودن متغیر وابسته می توانیم از تابع ()hist به شکل زیر استفاده کنیم.
hist(income.data$happiness)
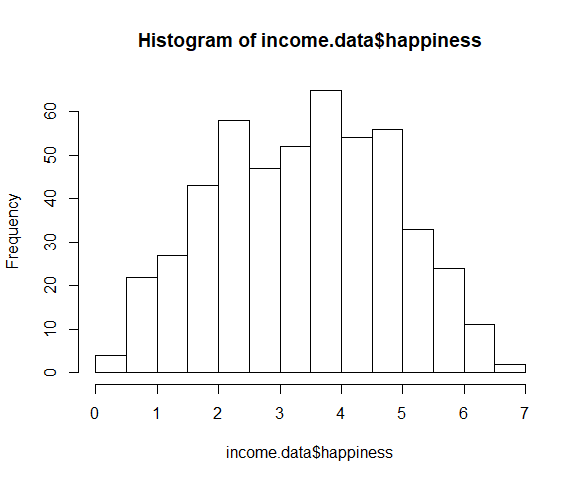
بیشتر مشاهدات در وسط توزیع قرار گرفته اند و یک نمودار زنگی شکل داریم، یعنی می توانیم با رگرسیون خطی ادامه دهیم.
3- رابطه خطی بین متغیر وابسته و مستقل(Linearity)
رابطه بین متغیر وابسته و مستقل باید خطی باشد. برای آزمون خطی بودن می توانیم از رسم یک نمودار scatter یا نقطه ای استفاده کنیم.
plot(happiness ~ income, data = income.data)
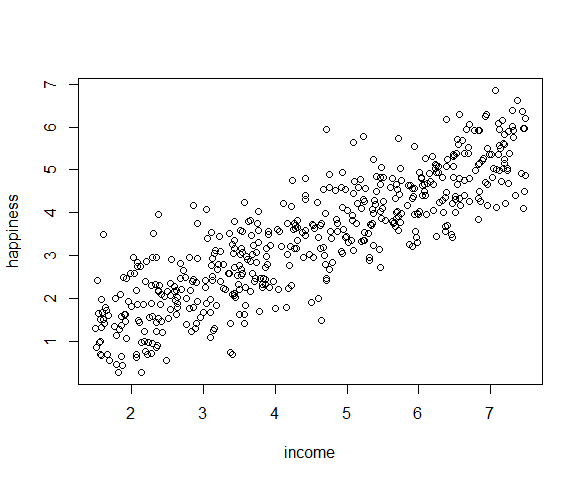
رابطه بین متغیر income و happiness تقریبا خطی به نظر می رسد، پس می توانیم به رگرسیون خطی ادامه دهیم.
4- واریانس همسانی
یعنی خطای پیش بینی در محدوده پیش بینی مدل به طور قابل توجهی تغییر نمی کند. می توانیم این مورد را بعد از تخمین مدل آزمون کنیم.
مدل خطی چندگانه
1- استقلال مشاهدات (عدم وجود خودهمبستگی)
برای بررسی فرض عدم وجود خودهمبستگی بین متغیرهای مستقل می توانیم از تابع ()cor استفاده کنیم.
cor(heart.data$biking, heart.data$smoking)
بعد از اجرای این کد خروجی برابر با 0.015 است. یعنی همبستگی بین متغیر smoking و biking فقط 1.5٪ است، که عدد بسیار کوچکی است. یعنی می توانیم هر دو متغیر را در مدل استفاده کنیم.
2- نرمال بودن (Normality)
برای آزمون نرمال بودن متغیر وابسته از تابع ()hist استفاده می کنیم.
hist(heart.data$heart.disease)
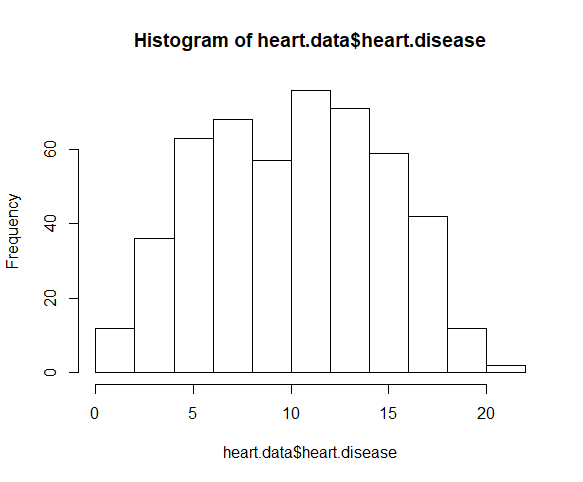
نمودار نشان می دهد توزیع داده ها به صورت زنگی شکل است. یعنی می توانیم به رگرسیون خطی ادامه دهیم.
3- خطی بودن (linearity)
برای بررسی وجود رابطه خطی، بین متغیرهای وابسته و مستقل می توانیم از دو نمودار scatter استفاده کنیم.
plot(heart.disease ~ biking, data=heart.data)
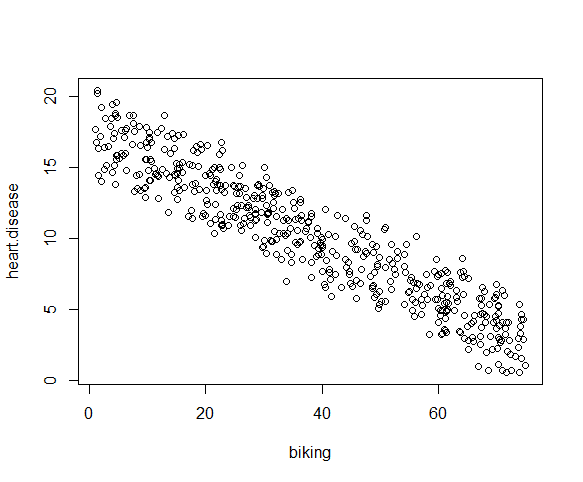
plot(heart.disease ~ smoking, data=heart.data)
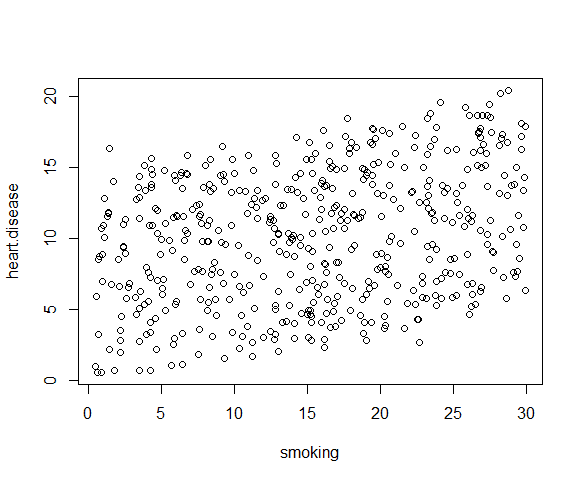
رابطه بین متغیرهای smoking و heart.disease کمی نامفهوم است. ولی می توان یک رابطه خطی در نظر گرفت. یعنی می توانیم مدل خطی مان را ادامه بدهیم.
4- واریانس همسانی
می توانیم بررسی واریانس همسانی را بعد از برآورد مدل آزمون کنیم.
قدم سوم: تحلیل رگرسیون خطی
حالا که فروض اساسی برای رگرسیون خطی را بررسی کرده ایم. می توانیم تحلیل رگرسیون خطی بین متغیرهای مستقل و متغیر وابسته را انجام دهیم.
می خواهیم رابطه خطی بین income و happiness که income در بازه 15000$و 75000$ است و happiness در بازه 1 تا 10 است، برای یک نمونه 500 تا را بررسی کنیم.
رگرسیون خطی ساده: Income و happiness
برای برآورد رگرسیون خطی در R نیاز به دو خط کدنویسی داریم. خط اول مدل را برآورد می کند و خط دوم نتایج مدل را به ما نشان می دهد.
income.happiness.lm <- lm(happiness ~ income, data = income.data) summary(income.happiness.lm)
نتایج را در جدول زیر می توانید ببینید.
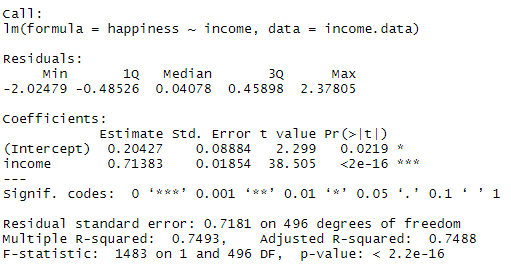
تفسیر جدول نتایج:
جدول نتایج ابتدا ضرایب مدل و سپس باقیمانده های مدل را به طور خلاصه بیان می کند.
بخش ضرایب:
در بخش Estimate ، ضریب بخش ثابت مدل برابر با 0.204 و ضریب income برابر با 0.713 است.
std. Error خطای استاندارد را نشان می دهد، که هر چه کوچکتر باشد بهتر است.
t value آماره t را نشان می دهد. هر چه آماره t بزرگتر باشد یعنی برآورد بهتری داشته ایم.
( Pr(>| t | ) ) در واقع پراب مدل را نشان می دهد و هر چه به صفر نزدیک باشد بهتر است. معمولا در تئوری های اقتصادسنجی پراب کمتر از 0.05 را سطح معنادار در نظر می گیرند. در مدل بالا پراب income حدود 0.001 شده است.
سه خط پایانی جدلو تشخیص مدل هستند. مهمترین چیزی که باید به آن توچه کرد مقدار p value است که در اینجا برابر با 2.2e-16 یا چیزی نزدکی به صفر است. که نشان می دهد مدل ما به خوبی با داده مطابقت دارد یا خیر.
با توجه به نتایج مدل می توانیم بگویم یک رابطه معنادار و مثبت بین income و happiness وجود دارد به طوریکه با افزایش یک واحد درآمد به مقدار 0.7 میزان شادی افزایش می یابد.
رگرسیون خطی چندگانه: رابطه بین دوچرخه سواری، سیگار کشیدن و بیماری قلبی
بیایید با هم رابطه خطی بین دوچره سواری، سیگار کشیدن و بیماری قلبی را برای داده های فرضی برای 500 شهر بررسی کنیم. نرخ دوچرخه سواری تا محل کار بین 1 تا 75 درصد، میزان سیگار کشیدن بین 0.5 تا 30 درصد و نرخ بیماری قلبی بین 0.5 تا 20.5 درصد است.
برای برآورد رابطه خطی بین بیماری قلبی به عنوان متغیر وابسته و سیگار کشیدن و دوچرخه سواری به عنوان متغیرهای مستقل، این کدها را در محیط R اجرا می کنیم.
heart.disease.lm<-lm(heart.disease ~ biking + smoking, data = heart.data) summary(heart.disease.lm)
جدول نتایج رگرسیون
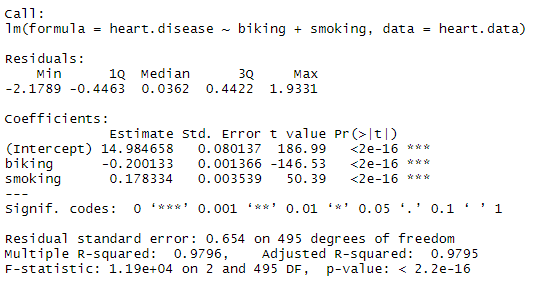
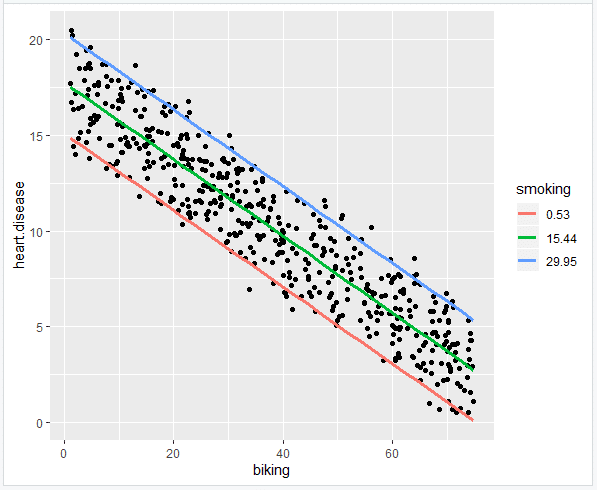
ضرایب برآورد شده مدل برای متغیر biking(دوچرخه سواری) برابر با 0.2- و برای متغیر smoking(سیگار کشیدن) برابر با 0.17 است.
این بدان معنی است که به ازای هر 1 درصد افزایش دوچرخه سواری، 0.2 درصد کاهش در بروز بیماری قلبی وجود دارد. این در حالی است که به ازای هر 1 درصد افزایش مصرف سیگار، 0.178 درصد افزایش در میزان بیماری قلبی وجود دارد.
در داده های فرضی ما، همه متغیرها با آماره t بزرگ و انحراف استاندارد بسیار کوچک معنادار شده اند. در عالم واقع ممکن است رابطه بین متغیرها به این روشنی نباشد.
قدم چهارم: بررسی همسانی واریانس
واریانس همسانی از فروض اساسی در برآورد مدل های خطی است، که باید بعد از برآورد مدل انجام دهیم.
رگرسیون خطی ساده
می توانیم از طریق تابع plot(income.happiness.lm) وارینس همسانی را چک کنیم.
par(mfrow=c(2,2)) plot(income.happiness.lm) par(mfrow=c(1,1))
دستور par(mfrow=c()) تعداد سطرها و ستون ها را برای رسم نمودار مشخص می کند. برای این مثال par(mfrow=c(2,2)) یک جدول 2*2 ایجاد می کند. اگر بخواهیم نمودارهای بزرگتر در یک سطر و ستون داشته باشیم باید به صورت par(mfrow=c(1,1)) تنظیم کنیم.
رسم باقیمانده های مدل را می توانیم در تصویر زیر ببینیم.
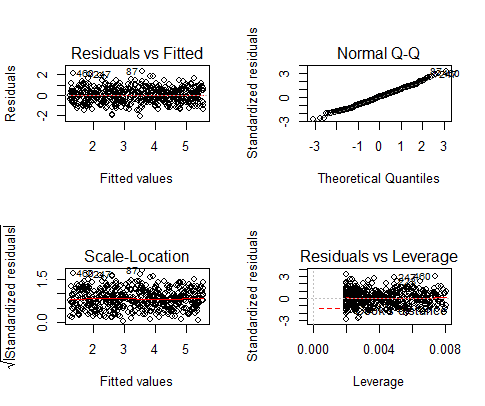
باقیمانده ها در واقع واریانس های غیرقابل توضیح هستند. آنها دقیقا شبیه خطای مدل نیستند ولی از روی باقیمانده ها، خطای مدل را محاسبه می کنند. بنابراین مشاهده یک بایاس در باقیمانده، نشان دهنده یک سوگیری در خطا است.
مهمترین چیزی که در بررسی باقیمانده ها باید به دنبال آن باشیم، خط های قرمزی است که در وسط نمودارها رسم شده اند. این خطوط قرمز نشان دهنده میانگین باقیمانده ها هستند که اساسا به صورت افقی و در وسط (نزدیک به صفر) رسم شده اند. یعنی هیچ نقطه پرت یا سوگیری در داده ها وجود ندارد که رگرسیون خطی را نامعتبر کند.
در نمودار Normal Q-Qplot که در سمت راست بالای نمودار قرار گرفته، می توانیم ببینیم که باقیمانده های واقعی مدل ما یک خط یک به یک است که بسیار شبیه یک مدل نظری خطی کامل است.
براساس این باقیمانده ها می توانیم بگوییم مدل ما واریانس ناهمسانی ندارد.
رگرسیون خطی چندگانه
ما باید بررسی کنیم که آیا مدلی که برآورد کرده ایم، بهترین برآورد است یا نه. برای همین با اجرای کدهای زیر می توانیم فرض واریانس همسانی را برای باقیمانده ها بررسی کنیم.
par(mfrow=c(2,2)) plot(heart.disease.lm) par(mfrow=c(1,1))
نتایج را در نمودارهای زیر می توانیم ببینیم
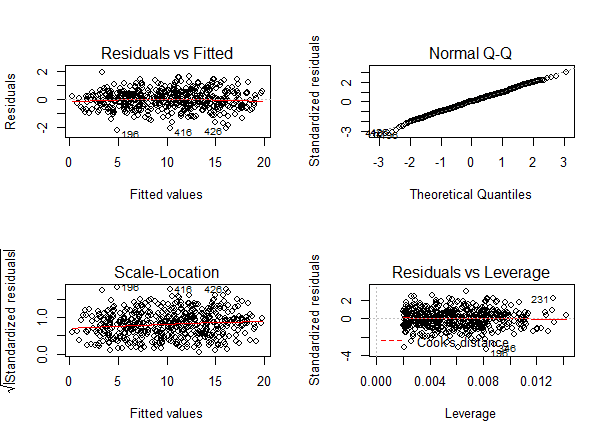
نمودارهای بالا شبیه به رگرسیون خطی ساده هستند. بنابراین واریانس ناهمسانی نداریم و این یعنی یک برآورد خوب انجام داده ایم.
قدم پنجم: مصورسازی نتایج با رسم نمودار
رگرسیون خطی ساده
مراحل زیر را باید برای مصورسازی نتایج در رگرسیون خطی انجام دهیم.
1-رسم یک نمودار نقطه ای(scatter plot) از داده ها
income.graph<-ggplot(income.data, aes(x=income, y=happiness))+
geom_point()
income.graph
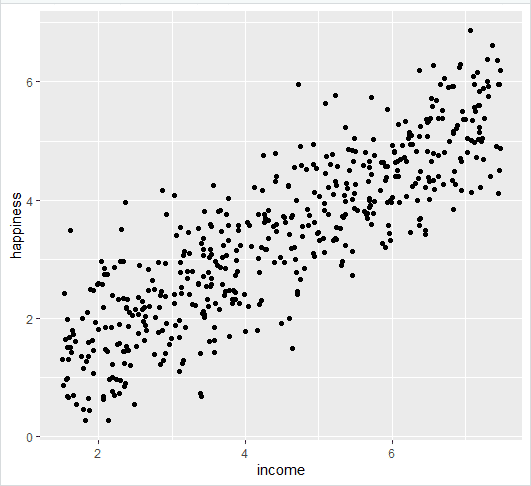
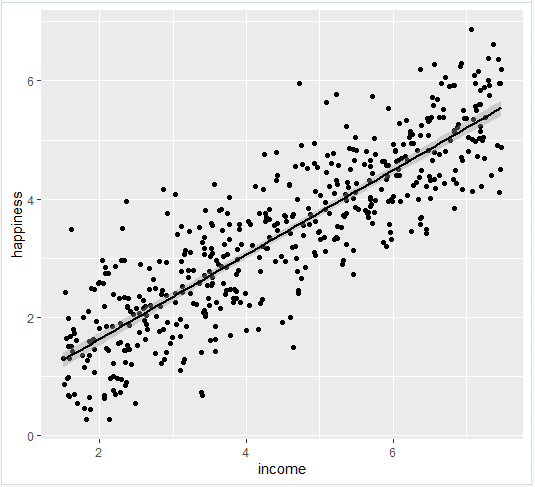
2- اضافه کردن خط رگرسیون خطی به نمودار قبلی
خط رگرسیون را با استفاده از ()geom_smooth و تایپ lm به عنوان روش خود برای ایجاد خط اضافه کنید. این خط رگرسیون خطی و همچنین خطای استاندارد برآورد (در این مورد +/- 0.01) را به عنوان یک نوار خاکستری روشن در اطراف خط اضافه می کند:
income.graph <- income.graph + geom_smooth(method="lm", col="black") income.graph
3- اضافه کردن معادله برای خط رگرسیون
income.graph <- income.graph + stat_regline_equation(label.x = 3, label.y = 7) income.graph
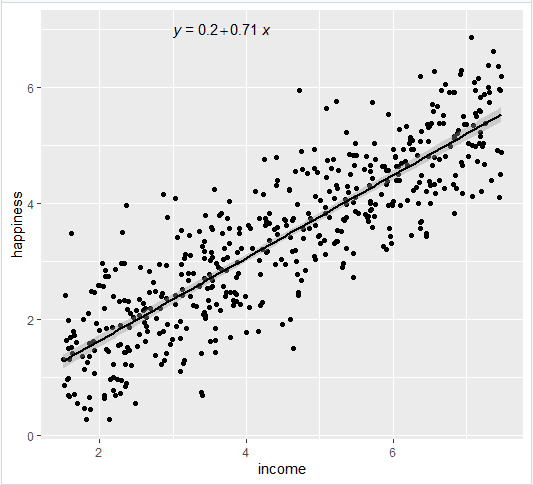
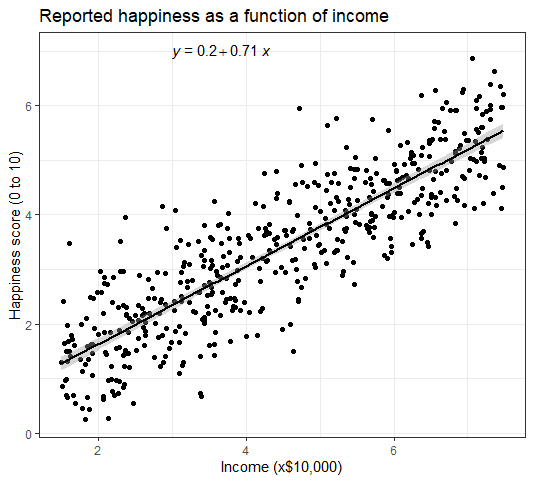
4- آماده سازی یک نمودار مرتب برای انتشار
می توانیم از تابع ()theme_bw برای رنگ بندی پس زمینه و همچنین از تابع ()labs برای تغییر لیبل ها استفاده کنیم.
income.graph +
theme_bw() +
labs(title = "Reported happiness as a function of income",
x = "Income (x$10,000)",
y = "Happiness score (0 to 10)")
این هم نمودار تر و تمیز برای استفاده در گزارش ها یا مقالات
رگرسیون خطی چندگانه
مصورسازی داده ها در رگرسیون خطی چندگانه کمی پیچیده تر از رگرسیون خطی ساده است. زیرا در این مدل ما دو پیش بینی داریم که مصور سازی آنها دشوار است.
برای ساده سازی ترسیم رابطه بین دوچرخه سواری و بیماری قلبی در سطوح مختلف سیگار کشیدن. سیگار کشیدن به عنوان عاملی با سه سطح، فقط به منظور نمایش روابط در داده های ما، در نظر گرفته می شود.
برای انجام مصورسازی داده های این مدل باید 7 مرحله زیر را انجام دهیم.
1- یک دیتا فریم جدید با اطالاعات مورد نیاز برای رسم نمودار ایجاد می کنیم
از تابع ()expand.grid برای ایجاد یک دیتافریم با پارامترهایی که نیاز داریم استفاده می کنیم.
در این تابع:
ابتدا دنباله ای از کمترین مقدار تا بالاترین مقدار از داده های دوچرخه سواری را ایجاد می کنیم. سپس
مقدار حداقل، میانگین و حداکثر سیگار کشیدن را در 3 سطح تعیین می کنیم، تا میزان بیماری قلبی را پیش بینی کنیم.
plotting.data<-expand.grid(
biking = seq(min(heart.data$biking), max(heart.data$biking), length.out=30),
smoking=c(min(heart.data$smoking), mean(heart.data$smoking), max(heart.data$smoking)))
این کدها یک دیتا فریم جدید در قسمت راست بالای نرم افزار Rstudio ایجاد می کند که با کلیک کردن بر روی آن می توانیم ببینیم.
2- پیش بینی مقادیر بیماری قلبی براساس مدل خطی
مقادیر پیش بینی را در یک ستون کنار دیتافریم جدید ذخیره می کنیم.
plotting.data$predicted.y <- predict.lm(heart.disease.lm, newdata=plotting.data)
3- رند کردن اعدا سیگار به دو اعشار
داده های smoking را رند می کنیم، این کار به ما کمک می کند تا موقع رسم نمودار راحتر باشیم.
plotting.data$smoking <- round(plotting.data$smoking, digits = 2)
4- تغییر متغیر سیگار کشیدن (smoking) به حالت فاکتور
ما می توانیم با تغییر متغیر smoking رابطه بین دوچرخه سواری و بیماری قلبی با سطوح مختلف سیگار کشیدن را ترسیم کنیم.
plotting.data$smoking <- as.factor(plotting.data$smoking)
5- رسم کردن نمودار داده های اصلی
heart.plot <- ggplot(heart.data, aes(x=biking, y=heart.disease)) + geom_point() heart.plot
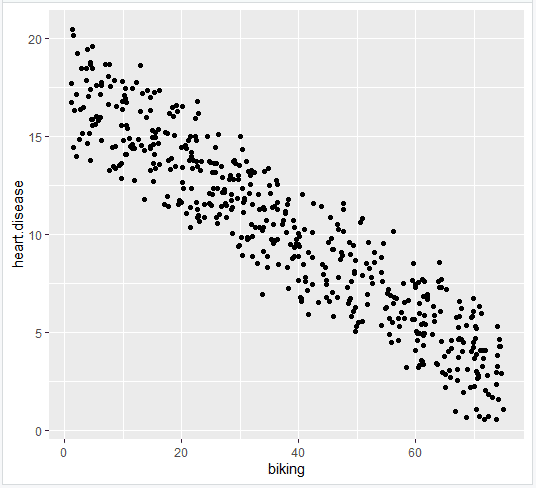
6- اضافه کردن خط رگرسیون
heart.plot <- heart.plot + geom_line(data=plotting.data, aes(x=biking, y=predicted.y, color=smoking), size=1.25) heart.plot
7- آماده سازی نمودار نهایی برای انتشار در مقاله
heart.plot <-
heart.plot +
theme_bw() +
labs(title = "Rates of heart disease (% of population) \n as a function of biking to work and smoking",
x = "Biking to work (% of population)",
y = "Heart disease (% of population)",
color = "Smoking \n (% of population)")
heart.plot
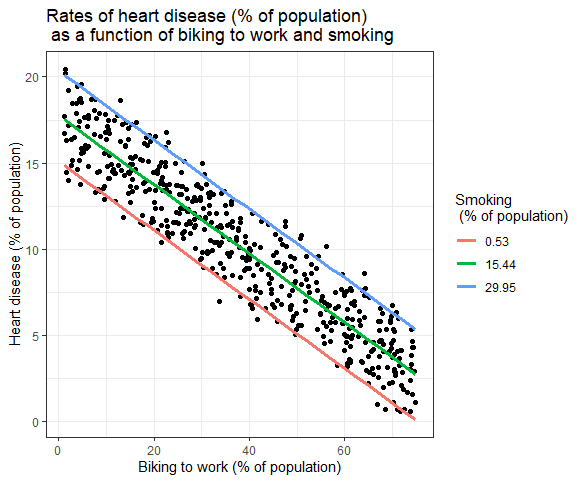
از آنجایی که این نمودار دارای دو ضریب رگرسیون است، تابع stat_regline_equation() در اینجا کار نخواهد کرد. اما اگر بخواهیم مدل رگرسیون خود را به نمودار اضافه کنیم، می توانیم این کار را به صورت زیر انجام دهیم:
heart.plot + annotate(geom="text", x=30, y=1.75, label=" = 15 + (-0.2*biking) + (0.178*smoking)")
قدم ششم: گزارش نتایج
علاوه بر نمودارها یک توضیح مختصر از نتایج مدل را می توانیم ارائه می دهیم.
نتایج رگرسیون خطی ساده
بر اساس نتایج، ما رابطه معناداری بین درآمد و خوشحالی پیدا کردیم ((p < 0.001, R2 = 0.73 ± 0.0193))، به صوریکه با افزایش یک واحد در درآمد، به میزان 0.73 درصد به میزان خوشحالی افزوده می شود.
نتایج رگرسیون خطی چند متغیره
با توجه به نتایج مدل، ما رابطه معناداری بین سیگار کشیدن، دوچرخه سواری و بروز بیماری قلبی پیدا کردیم. به طوریکه با افزایش 1 درصد در دوچرخه سواری بروز بیماری قلبی 0.2 درصد کاهش پیدا می کند. همچنین با افزایش 1 درصدی سیگار کشیدن، بروز بیماری قلبی 0.178 درصد افزایش می یابد.




بسیار عالی. مرررسی از وقتی که میزارید و محتوای کاربردی تولید می کنید. متشکرم
ممنون از شما مرسی که مطالب وبسایت رو دنبال می کنید
مقاله کاملی بود. اگر مقالات مرتبط در رابطه با سایر رگرسیونها بزارید هم عالی میشه.
ممنون که وقت میزارید و محتوا کاربردی تولید می کنید.
با تشکر
سلام خوشحالم که براتون مفید بوده، به روی چشم مقالات دیگه با حل مثال در هفته های آتی منتشر میشه.