 مدرسه تخصصی اقتصاد |
مدرسه تخصصی اقتصاد |
تجزیه و تحلیل داده های پانل یک روش بسیار قدرتمند برای تحلیل داده های تابلویی برای گروه ها، شرکت ها یا کشورها در زمان های مختلف است. در این مقاله به تجزیه و تحلیل داده های پانل به صورت گام به گام در stata می پردازیم.
۱- تجزیه و تحلیل داده های پانل چیست؟
تجزیه و تحلیل داده های پانل با عنوان هایی مانند، تجزیه و تحلیل داده های طولی یا تجزیه و تحلیل اندازه گیری های مکرر نیز شناخته می شود. تجزیه و تحلیل داده های پانل یک روش آماری است که تجزیه و تحلیل داده هایی استفاده می شود که در آن مشاهدات روی یک مجموعه از افراد یا واحدها در طول زمان انجام می شود. این نوع داده ها معمولاً در زمینه هایی مانند اقتصاد، علوم اجتماعی و تحقیقات پزشکی استفاده می شود. محققان معمولاً علاقه مند به درک این هستند که متغیرها در طول زمان چگونه تغییر می کنند یا چگونه با یکدیگر مرتبط هستند.
۲- چرا در تجزیه و تحلیل داده های پانل از Stata استفاده کنیم؟
تجزیه و تحلیل داده های پانل در stata مزیت هایی دارد که در ادامه به برخی از آنها می پردازیم. برای اطلاعات بیشتر مقاله ببینید تجزیه و تحلیل داده های پانل در stata را ببینید.
۱- کنترل ناهمگنی
یکی از مزیت های اصلی این است که به محققان اجازه می دهد ناهمگونی مشاهده نشده در داده ها را کنترل کنند، که می تواند منجر به تخمین های مغرضانه از اثرات متغیرها بر نتایج شود. با گنجاندن اثرات ثابت در سطح فردی، تجزیه و تحلیل دادههای پانل میتواند ویژگیهای خاص فردی، را که در طول زمان ثابت هستند و ممکن است با متغیرهای مورد علاقه مرتبط باشند محاسبه کند.
۲- بررسی متغیرها در طول زمان
مزیت دیگر تجزیه و تحلیل داده های تابلویی این است که به محققان اجازه می دهد تا اثرات متغیرها را در طول زمان بررسی کنند. با گنجاندن متغیرهای کمکی متغیر با زمان، تجزیه و تحلیل دادههای تابلویی میتواند تغییرات متغیرها را در طول زمان و نحوه تأثیر آنها بر نتایج را ثبت کند. این امر آن را به روشی ایده آل برای مطالعه فرآیندهای پویا و تأثیر مداخلات سیاستی تبدیل می کند.
۳- stata ابزاری قدرتمند برای تجزیه و تحلیل داده های پانل است
تجزیه و تحلیل داده های پانل در Stata همچنین طیف وسیعی از ابزارها و روش های قدرتمند را برای کاوش، تجسم و مدل سازی داده ها ارائه می دهد. دستورات داخلی Stata برای تجزیه و تحلیل داده های پانل به محققان اجازه می دهد تا به راحتی مدل های اثرات ثابت و تصادفی، مدل های پانل پویا و سایر روش های پیشرفته را تخمین بزنند. علاوه بر این، قابلیتهای گرافیکی Stata ایجاد تجسمهایی از دادههای پانل را آسان میکند که میتواند به کاوش دادهها و تفسیر مدل کمک کند.
به طور کلی، تجزیه و تحلیل داده های پانل در Stata ابزار قدرتمندی برای تجزیه و تحلیل داده های طولی و کاوش روابط پویا بین متغیرها در طول زمان در اختیار محققان قرار می دهد.
۳- توضیحاتی درباره داده های پانل
زمانیکه میخواهیم با داده های پانل در stata کار کنیم، باید به استتا اعلام کنیم که داده های ما از نوع پانل هستند.
مرحله اول: وارد کردن داده ها
با وارد کردن کد زیر در قسمت command استتا، داده وارد نرم افزار stata می شوند. داده های استفاده شده در این مقاله آموزشی هستند.
use https://dss.princeton.edu/training/Panel101_new.dta
در صورتی که می خواهید داده های خودتان را وارد نرم افزار کنید، می توانید از مقاله نحوه وارد کردن داده ها به نرم افزار Stata کمک بگیرید.
مرحله دوم: تنظیم کردن داده ها در stata
برای تنظیم داده ها به عنوان داده پانل در stata کد زیر را در قسمت command استتا تایپ می کنیم.
xtset country year
Stata یک پیام به شکل زیر به ما نشان می دهد.
xtset country year
Panel variable: country (strongly balanced)
Time variable: year, 2011 to 2020
Delta: 1 unit
اصطلاح «(strongly balanced)» به این واقعیت اشاره دارد که همه کشورها دادههای مربوط به همه سالها را دارند. به عنوان مثال، اگر کشوری برای هر سال داده ای نداشته باشد، داده ها نامتعادل هستند. در حالت ایده آل، شما می خواهید یک مجموعه داده متعادل داشته باشید، اما همیشه اینطور نیست. با این وجود، همچنان می توانید مدل را اجرا کنید.
توجه: اگر بعد از استفاده از xtset با خطای زیر مواجه شدید:
string variables not allowed in varlist; country is a string variable
باید country را به حالت عددی تبدیل کنیم. برای این کار کد زیر را در قسمت کامند تایپ و اجرا می کنیم.
encode country, gen(country1)
سپس بجای متغیر country از متغیر country1 به شکل زیر استفاده می کنیم.
xtset country1 year
۴- تخمین مدل داده های پانل در Stata
در این مقاله درباره دو مدل پایه ای رایج برای داده های پانل بحث می کنیم.
- Fixed Effects Method
- Random Effects Method
تفاوت اصلی بین مدلهای اثرات ثابت و تصادفی در نحوه برخورد آنها با ویژگیهای خاص فردی است. مدلهای اثرات ثابت (xtreg، fe) فرض میکنند که ویژگیهای خاص فردی مشاهده نشده در طول زمان ثابت هستند و در بین افراد نیز یکسان اند. در این مورد، مدل تأثیر متغیرهای مشاهده شده را بر روی نتیجه تخمین می زند و در عین حال ویژگی های خاص فردی مشاهده نشده را کنترل می کند. از سوی دیگر، مدلهای اثرات تصادفی (xtreg، re) فرض میکنند که ویژگیهای خاص فردی مشاهده نشده تصادفی هستند و در بین افراد متفاوت هستند. در این مورد، مدل تأثیر متغیرهای مشاهدهشده را بر نتیجه تخمین میزند و در عین حال این امکان را میدهد که ویژگیهای خاص فردی مشاهده نشده با عبارت خطا مرتبط باشند.
۴.۱- تخمین مدل پانل با اثرات ثابت در Stata
برای تخمین مدل با اثرات ثابت از کد زیر استفاده می کنیم.
xtreg y x1 x2, fe
با اجرای کد بالا، stata نتایج زیر را به ما نشان می دهد.
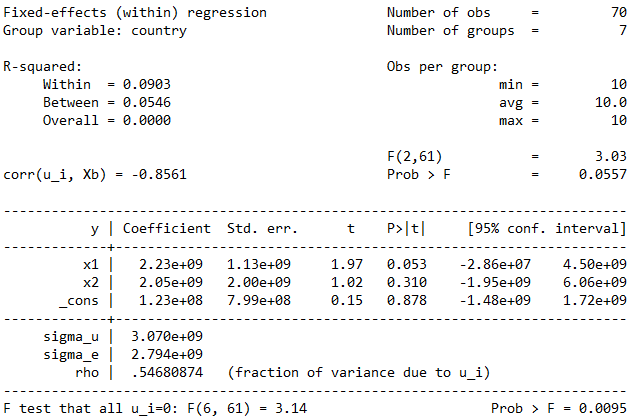
تجزیه و تحلیل نتایج داده های پانل در Stata
در مدل بالا تاثیر متغیرهای x1 و x2 را روی متغیر y بررسی کرده ایم. ضرایب یا Coefficient میزان و نوع تاثیر متغیرهای x1 و x2 را نشان میدهد. std. err خطای استاندارد هرچقدر کوچکتر باشد بهتر است و t هر چقدر بزرگتر باشد یعنی مدل بهتری تخمین زده ایم. P>|t| پراب ها با توجه به فاصله اطمینان می توانند در سطح ۱ ٪ ، ۵٪ و ۱۰٪ معناداری متغیرها در مدل را نشان دهند. در مدل بالا متغیر x1 در سطح ۱۰٪ معنادار شده است و با تغییر هر واحد در x1 معادل ۲.۲۳٪ y تغییر می کند.
۴.۲- تخمین مدل پانل با اثرات تصادفی
برای تجزیه و تحلیل مدل داده های پانل با اثرات تصادفی در Stata از دستور زیر استفاده می کنیم.
xtreg y x1 x2, re

در مدل بالا هیچ متغیری در مدل پانل با اثرات تصادفی معنادار نشده است.
۵- اثرات ثابت یا اثرت تصادفی
با استفاده از آزمون هاسمن یا Husman Test این موضوع را مشخص می کنیم.
برای اینکه بتوانیم آزمون هاسمن را اجرا کنیم، اول باید مدل پانل با اثرات ثابت را برآورد کنیم و نتایج را در stata ذخیره کنیم و سپس مدل پانل با اثرات تصادفی را برآورد کنیم و نتایج را در stata ذخیره کنیم. در مرحله آخر آزمون هاسمن را اجرا می کنیم.
xtreg y x1 x2, fe estimates store fixed xtreg y x1 x2, re estimates store random hausman fixed random

قانون تصمیم گیری:
اگر Prob > chi2 < 0.05 باشد از مدل با اثرات ثابت استفاده می کنیم، در غیر این صورت از مدل با اثرات تصادفی استفاده می کنیم. در این مدل چون Prob > chi2 = 0.0500 است از مدل با اثرات تصادفی استفاده می کنیم.