 مدرسه تخصصی اقتصاد |
مدرسه تخصصی اقتصاد |
تحلیل داده های پانل یکی از روش های مرسوم در اقتصادسنجی است. تحلیل پانل دیتا به ما کمک می کند تا داده های مقطعی و سری زمانی را به طور همزمان مورد بررسی قرار دهیم. این روش هم در کسب و کارها و هم در سیاست گذاری های کلان اقتصادی مورد استفاده قرار می گیرد. زمانیکه بخواهیم رفتار اقتصادی چند شرکت یا چند کشور را در طول زمان مورد بررسی قرار دهیم، با داده های پانل سروکار داریم. اگر هیچ داده گم شده ای در طول دوره مطالعه نداشته باشیم، یک پانل متوازن یا Balanced داریم. در صورتی که داده گم شده داشته باشیم با پانل نامتوازن یا Unbalanced مواجه هستیم.
اثرات ثابت یا اثرات تصادفی
مدل با اثرات ثابت یا Fixed Effect:
اثرات ثابت رابطه بین متغیر وابسته و متغیرهای مستقل را در یک نهاد (کشور، شرکت، خانوار و غیره) بررسی می کند. هر نهاد دارای ویژگی های منحصربه فرد خود است که ممکن است بر متغیر پیش بینی کننده تاثیر بگذارد. برای مثال سن، جنسیت و یا سایر ویژگی ها ممکن است بر یک سیاست یا رفتار تاثیر بگذارد. در مدل با اثرات ثابت ما به دنبال کنترل تاثیر این متغیرها هستیم، تا بتوانیم اثرات خالص پیش بینی کننده ها را بر متغیر نتیجه بررسی کنیم.
اثرات تصادفی یا Random Effect:
اگر دلیلی برای این باور دارید که تفاوت بین موجودیت ها تا حدی بر متغیر وابسته شما تأثیر می گذارد، باید از اثرات تصادفی استفاده کنید. در مدل با اثرات تصادفی، باید آن ویژگی های فردی را که ممکن است بر پیش بینی کننده ها تاثیر بگذارند یا خیر را مشخص کنید. یکی دیگر از مزایای مدل با اثرات تصادفی این است که می توانیم متغیرهای تغییر ناپذیر زمان مانند جنسیت را در مدل وارد کنیم. در مدل با اثرات ثابت تاثیر این متغیرها توسط عرض از مبدا جذب می شوند.
چگونه بهفمیم مدل با اثرات ثابت انتخاب کنیم یا مدل با اثرات تصادفی؟
معیار تصمیم گیری انتخاب بین مدل با اثرات ثابت و مدل با اثرات تصادفی، اجرای آزمون هاسمن است. به طوریکه فرضیه صفر: مدل ترجیحی اثرات تصادفی در مقابل مدل جایگزین اثرات ثابت است. آزمون هاسمن، آزمایش می کند که آیا خطاهای منحصر به فرد با رگرسیون همبستگی دارند یا خیر؟ فرضیه صفر این است که آنها همبستگی ندارند.
برای انجام آزمون هاسمن، ابتدا مدل با اثرات ثابت را برآورد می کنیم و نتایج را ذخیره می نماییم، سپس مدل با اثرات تصادفی را برآورد می کنیم و نتایج را ذخیره می نماییم، در آخر آزمون هاسمن را اجرا می کنیم.
وارد کردن داده های پانل در R
برای وارد کردن داده های پانل نیز مانند سایر داده ها عمل می کنیم، برای جزئیات بیشتر به مقاله نحوه وارد کردن داده ها در r مراجعه کنید. در این مقاله از داده های آموزشی تهیه شده توسط دانشگاه پرینستون استفاده می کنیم. با استفاده از کتابخانه foreign داده ها را وارد R studio می کنیم.
library(foreign)
Panel <- read.dta("http://dss.princeton.edu/training/Panel101.dta")
View(Panel)
مدل با اثرات ثابت (Fixed Effect)
با استفاده از (package) یا بسته آماری plm مدل پانل را برآورد می کنیم.
install.packages("plm")
library(plm)
fixed <- plm(y ~ x1, data=Panel, index=c("country", "year"), model="within")
summary(fixed)
برای تنظیم داده های پانل از index استفاده می کنیم، که ممکن است در همه مواقع نیاز نباشد.
ما از model=”within” برای مدل Fixed Effect استفاده کرده ایم
در واقع پکیج plm مدل های زیادی را می تواند برآورد کند که در زیر به چند مورد می پردازیم.
- مدل با اثرات ثابت (within)
- مدل با اثرات تصادفی (random)
- مدل پولد (pooling)
- مدل تفاضل مرتبه اول (fd)
- مدل between: (between)
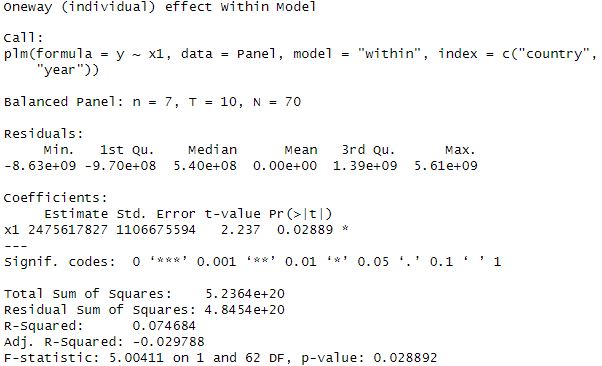
معادله y=a+bx1 را برآورد کردیم. ضریب متغیر x1 یا b را اینگونه تحلیل می کنیم، اول از هر چیز pr(>|t|) را باید ببینیم که آیا کمتر از 0.05 یا نهایتا 0.10 است یا خیر، اگر کمتر از 0.05 باشد؛ می گوییم متغیر ما در سطح 95 درصد معنادار شده است، در معادله ما متغیر x1 در سطح 0.05 درصد معنادار شده است؛ زیرا پراب آن 0.02889 است. ضریب x1 تاثیر میزان تغییر 1 واحد x1 بر روی y را نشان می دهد. p-value دوم که در خط آخر جدول نتایج آمده است، نشان می دهد که آیا مدل به طور کلی معنادار است یا نه. در این مدل چون فقط یک متغیر داریم p-value با pr(>|t|) برابر است.
مدل با اثرات تصادفی (Random Effect)
در مدل با اثرات تصادفی مانند مدل با اثرات ثابت، از کتابخانه plm استفاده می کنیم. با این تفاوت که هنگام اجرای مدل باید random را انتخاب کنیم. برای اجرای مدل با اثرات تصادفی از کدهای زیر استفاده کنید.
random <- plm(y ~ x1, data=Panel, index=c("country", "year"), model="random")
summary(random)
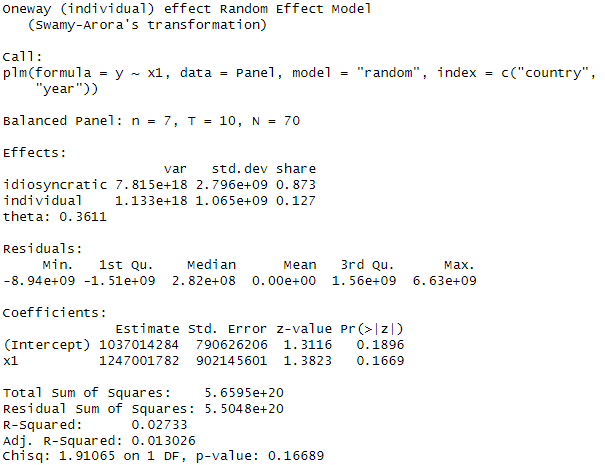
خروجی مدل random effect نشان می دهد که متغیر x1 در این مدل معنادار نشده است. هر چقد تعداد متغیرهای مستقل در مدل بیشتر باشد و به درستی تبیین شوند، مدل به طور کلی از معناداری بیشتری برخوردار می شود.
اثرات ثابت یا اثرات تصادفی
با استفاده از آزمون هاسمن می توانیم مدل مناسب برای تحلیل داده های پانل را انتخاب کنیم. ابتدا مدل با اثرات ثابت را برآورد می کنیم، سپس مدل با اثرات تصادفی را برآورد می کنیم و در نهایت با استفاده از دستور phtest آزمون هاسمن را اجرا می کنیم.
library(plm)
fixed <- plm(y ~ x1, data=Panel, index=c("country", "year"), model="within") #fixed model
random <- plm(y ~ x1, data=Panel, index=c("country", "year"), model="random") #random model
phtest(fixed,random) #Hausman test

معیار انتخاب مدل p-value است. اگر p-value کمتر از 0.05 باشد، از مدل با اثرات ثابت استفاده می کنیم. اگر p-value بزرگتر از 0.05 باشد، از مدل با اثرات تصادفی استفاده می کنیم.


