مدرسه تخصصی اقتصاد |
مدرسه تخصصی اقتصاد |
در این مقاله نحوه انجام رگرسیون خطی در پایتون را با حل یک مثال و با استفاده از محیط spyder توضیح می دهم.
ما در رگرسیون خطی ساده به دنبال بهترین برآورد که خطای مدل را حداقل می کند، در رابطه خطی بین دو متغیر وابسته و مستقل هستیم.
در مدل رگرسیون خطی ساده، تنها از یک متغیر مستقل استفاده می کنیم.
برای شروع کار ابتدا دادهای زیر را دانلود کنید و در کامپیوتر خودتون در یک مسیر مشخص ذخیره نمایید.
راهنمای گام به گام رگرسیون خطی ساده در python با حل یک مثال
گام اول: نصب و فراخوانی کتابخانه ها
برای برآورد یک معادله رگرسیون خطی ساده در پایتون نیاز به فراخوانی کتابخانه های زیر داریم.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import statsmodels.api as sm
گام دوم: وارد کردن داده ها به محیط پایتون
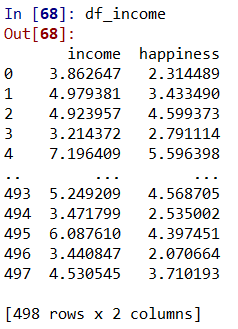
df_income = pd.read_csv('C:/Users/ATLAS/Desktop/income.data.csv')
df_income = df_income.drop('Unnamed: 0', axis=1)
df_income
df_income.describe()
خط اول در قطعه کد بالا داده ها که با فرمت csv هستند را از طریق کتابخانه panda وارد پایتون می کند. با کلیک کردن بر روی variable explorer در قسمت راست بالای محیط spyder می توانیم داده ها را ببینیم. داده های ما در فایلی که وارد پایتون کرده ایم، یک ستون حاوی تعداد مشاهدات داره که بدون نام هم ذخیره شده است. برای حذف این ستون اضافی از خط دوم قطعه کد بالا استفاده می کنیم.
در خط سوم چند مشاهده اول و اخرین مشاهده را می توانیم در قسمت IPthon Console ببینیم.
در خط چهارم خلاصه ای از داده ها شامل مقدار حداقل، میانگین، انحراف معیار و حداکثر را می توانیم ببینیم.

گام سوم: بررسی فروض اساسی در رگرسیون خطی
۴ فرض اساسی از قبیل استقلال مشاهدات(عدم وجود خودهمبستگی)، خطی بودن، نرمال بودن و واریانس ناهمسانی را باید در رگرسیون خطی بررسی کنیم.
۱- استقلال مشاهدات(عدم وجود خود همبستگی)
در مدل رگرسیون خطی ساده چون فقط یک متغیر مستقل داریم، بنابراین نیازی به چک کردن این فرض نیست.
۲- خطی بودن
بررسی رابطه خطی بین متغیر وابسته و متغیر مستقل
plt.scatter(df_income['happiness'], df_income['income'], color = 'lightcoral')
plt.title('happiness vs income')
plt.xlabel('income')
plt.ylabel('Happiness')
plt.box(False)
plt.show()
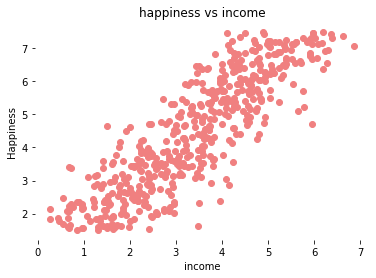
نمودار بالا یک رابطه خطی بین متغیر شادی و درآمد را تایید می کند.
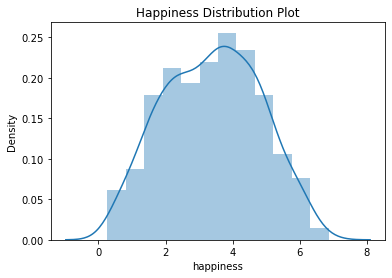
۳- نرمال بودن داده ها (Normality)
با اجرای کدهای زیر و با استفاده از کتابخانه seaborn توزیع متغیر شادی را می توانیم ببنیم.
plt.title('Happiness Distribution Plot')
sns.distplot(df_income['happiness'])
plt.show()
۴- واریانس ناهمسانی
بعد از تخمین رگرسیون خطی ساده در پایتون، واریانس ناهمسانی را چک می کنیم.
گام چهارم: رگرسیون خطی ساده در پایتون
حالا که فروض اساسی برای رگرسیون خطی را بررسی کرده ایم. می توانیم تحلیل رگرسیون خطی بین متغیرهای مستقل و متغیر وابسته را انجام دهیم.
می خواهیم رابطه خطی بین income و happiness که income در بازه ۱۵۰۰۰$و ۷۵۰۰۰$ است و happiness در بازه ۱ تا ۱۰ است، برای یک نمونه ۵۰۰ تا را بررسی کنیم.
y = df_income['happiness'] # dependent variable x = df_income['income'] # independent variable x = sm.add_constant(x) # adding a constant lm = sm.OLS(y,x).fit() # fitting the model lm.predict(x) lm.summary()
اولین کار این است که متغیر وابسته و متغیرهای مستقل را تعیین کنیم. بعد بخش ثابت مدل را تعریف می کنیم.
در قسمت های بعدی مدل را تخمین می زنیم و با اجرای ()lm.summary می توانیم نتایج را در قیمت console ببینیم.
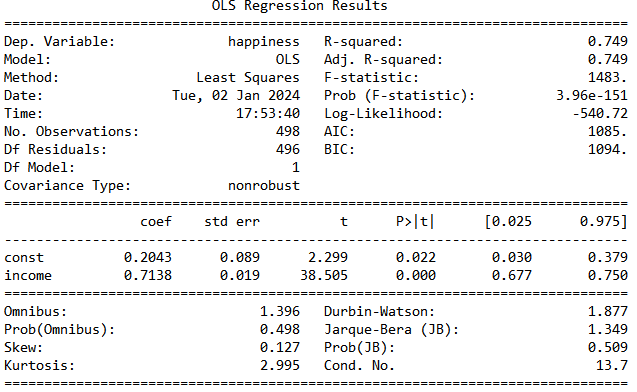
تفسیر جدول نتایج:
بخش ضرایب:
در بخش Estimate ، ضریب بخش ثابت مدل برابر با ۰.۲۰۴ و ضریب income برابر با ۰.۷۱۳ است.
std. Error خطای استاندارد را نشان می دهد، که هر چه کوچکتر باشد بهتر است.
t value آماره t را نشان می دهد. هر چه آماره t بزرگتر باشد یعنی برآورد بهتری داشته ایم.
( Pr(>| t | ) ) در واقع پراب مدل را نشان می دهد و هر چه به صفر نزدیک باشد بهتر است. معمولا در تئوری های اقتصادسنجی پراب کمتر از ۰.۰۵ را سطح معنادار در نظر می گیرند. در مدل بالا پراب income حدود ۰.۰۰۱ شده است.
با توجه به نتایج مدل می توانیم بگویم یک رابطه معنادار و مثبت بین income و happiness وجود دارد به طوریکه با افزایش یک واحد درآمد به مقدار ۰.۷ میزان شادی افزایش می یابد.
گام چهارم: بررسی باقیمانده های مدل رگرسیون خطی
۱- واریانس ناهمسانی
با استفاده از آزمون white واریانس ناهمسانی برا باقیمانده های مدل را چک می کنیم.
import statsmodels.api as sm from statsmodels.stats.diagnostic import het_white from statsmodels.compat import lzip model = sm.OLS(y,x).fit() #The test white_test = het_white(model.resid, model.model.exog) #Zipping the array with labels names = ['Lagrange multiplier statistic', 'p-value','f-value', 'f p-value'] lzip(names,white_test)

اگر p-value کمتر از ۰.۰۵ باشد، واریانس ناهمسانی داریم. نتایج بالا نشان می دهد، واریانس ناهمسانی نداریم.
۲- بررسی همخطی
همخطی زمانی رخ می هد که متغیرهای مستقل مدل با یک دیگر همبستگی داشته باشند. اگر درجه همخطی زیاد باشد می تواند در تفسیر نتایج مدل اختلال ایجاد کند. در مدل خطی ساده چون فقط یک متغیر مستقل داریم، بنابراین نیازی به چک کردن همخطی نیست.
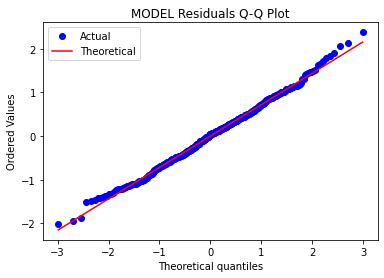
۳- بررسی نرمال بودن توزیع خطای مدل
چرا باید نرمال بودن توزیع خطای مدل را بررسی کنیم؟
زیرا در محاسبه فواصل اطمینان می تواند مشکل ایجاد کند. چولگی می تواند به دلیل وجود نقاط پرت باشد و این می تواند در هنگام تخمین پارامتر، سوگیری ایجاد کند.
قوی ترین راه برای انجام این کار توسط نمودار احتمال Q-Q. Quantile-Quantile با رسم باقیمانده ها است.
# Errors are normally distributed
from scipy import stats
stats.probplot(model.resid, dist="norm", plot= plt)
plt.title("MODEL Residuals Q-Q Plot")
plt.legend(['Actual','Theoretical'])
گام ششم: مصور سازی نتایج رگرسیون
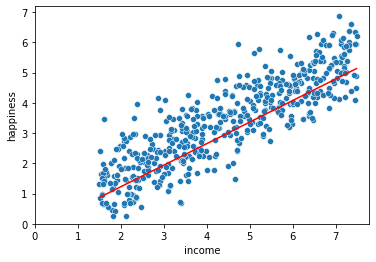
در بخش مصورسازی نتایج رگرسیون اول باید تابعی که تخمین زده ایم را در پایتون تعریف کنیم.
# Linear equation: 𝑦 = 𝑎𝑥 + 𝑏 y_pred = 0.7138 * x['income'] - 0.2043
در بخش بعدی خط برآورد شده از بین مشاهدات را رسم می کنیم.
# Linear Regression Plot import seaborn as sns import matplotlib.pyplot as plt # plotting the data points sns.scatterplot(x=x['income'], y=y) #plotting the line sns.lineplot(x=x['income'],y=y_pred, color='red') #axes plt.xlim(0) plt.ylim(0) plt.show()